Parsing des sensibilités
Le jeu de données utilisé ici est sensitivity_godiva.
Comme dans le cas précédent les résultats sont stockés dans la liste des réponses. Le Browser simplifie l’accès à des données grâce à la possibilité de sélection sur les métadonnées.
[1]:
from valjean.eponine.tripoli4.parse import Parser
t4vv_sg = 'sensitivity_godiva.d.res.ceav5'
# scan du jeu de données
t4p = Parser(t4vv_sg)
# parsing du dernier batch
t4pres = t4p.parse_from_index()
# clefs disponibles dans le dictionnaire de résultats
list(t4pres.res.keys())
INFO parse: Parsing sensitivity_godiva.d.res.ceav5
INFO parse: Successful scan in 0.171534 s
INFO parse: Successful parsing in 0.152186 s
[1]:
['list_responses', 'keff_auto', 'batch_data', 'run_data']
[2]:
lresp = t4pres.res['list_responses']
len(lresp)
[2]:
18
Le nombre peut être plus grand qu’attendu par la lecture du jeu de données car chaque résultat consistue une entrée dans le dictionnaire, soit chaque résultat dont la valeur d’une métadonnée varie.
[3]:
for i, resp in enumerate(lresp):
print('Response {0}: clefs = {1}'.format(i, sorted(resp.keys())))
Response 0: clefs = ['keff_estimator', 'response_function', 'response_index', 'response_type', 'results']
Response 1: clefs = ['keff_estimator', 'response_function', 'response_index', 'response_type', 'results']
Response 2: clefs = ['keff_estimator', 'response_function', 'response_index', 'response_type', 'results']
Response 3: clefs = ['keff_estimator', 'response_function', 'response_index', 'response_type', 'results']
Response 4: clefs = ['keff_estimator', 'response_function', 'response_index', 'response_type', 'results']
Response 5: clefs = ['keff_estimator', 'response_function', 'response_index', 'response_type', 'results']
Response 6: clefs = ['keff_estimator', 'response_function', 'response_index', 'response_type', 'results']
Response 7: clefs = ['response_function', 'response_index', 'response_type', 'results', 'sensitivity_index', 'sensitivity_nucleus', 'sensitivity_reaction', 'sensitivity_type']
Response 8: clefs = ['response_function', 'response_index', 'response_type', 'results', 'sensitivity_index', 'sensitivity_nucleus', 'sensitivity_reaction', 'sensitivity_type']
Response 9: clefs = ['response_function', 'response_index', 'response_type', 'results', 'sensitivity_index', 'sensitivity_nucleus', 'sensitivity_reaction', 'sensitivity_type']
Response 10: clefs = ['response_function', 'response_index', 'response_type', 'results', 'sensitivity_index', 'sensitivity_nucleus', 'sensitivity_reaction', 'sensitivity_type']
Response 11: clefs = ['response_function', 'response_index', 'response_type', 'results', 'sensitivity_index', 'sensitivity_nucleus', 'sensitivity_reaction', 'sensitivity_type']
Response 12: clefs = ['response_function', 'response_index', 'response_type', 'results', 'sensitivity_index', 'sensitivity_nucleus', 'sensitivity_reaction', 'sensitivity_type']
Response 13: clefs = ['response_function', 'response_index', 'response_type', 'results', 'sensitivity_index', 'sensitivity_nucleus', 'sensitivity_reaction', 'sensitivity_type']
Response 14: clefs = ['response_function', 'response_index', 'response_type', 'results', 'sensitivity_index', 'sensitivity_nucleus', 'sensitivity_reaction', 'sensitivity_type']
Response 15: clefs = ['response_function', 'response_index', 'response_type', 'results', 'sensitivity_index', 'sensitivity_nucleus', 'sensitivity_reaction', 'sensitivity_type']
Response 16: clefs = ['response_function', 'response_index', 'response_type', 'results', 'sensitivity_index', 'sensitivity_nucleus', 'sensitivity_reaction', 'sensitivity_type']
Response 17: clefs = ['response_function', 'response_index', 'response_type', 'results', 'sensitivity_index', 'sensitivity_nucleus', 'sensitivity_reaction', 'sensitivity_type']
On construit donc un Browser pour nous faciliter la tâche.
[4]:
t4b = t4pres.to_browser()
print(t4b)
Browser object -> Number of content items: 22, data key: 'results', available metadata keys: ['index', 'keff_estimator', 'response_function', 'response_index', 'response_type', 'sensitivity_index', 'sensitivity_nucleus', 'sensitivity_reaction', 'sensitivity_type']
-> Number of globals: 6
[5]:
for k in list(t4b.keys()):
print("{0} -> {1}".format(k, list(t4b.available_values(k))))
response_function -> ['KEFFS', 'IFP ADJOINT WEIGHTED KEFF SENSITIVITIES']
response_type -> ['keff', 'sensitivity', 'keff_auto']
response_index -> [0, 1]
keff_estimator -> ['KSTEP', 'KCOLL', 'KTRACK', 'KSTEP-KCOLL', 'KSTEP-KTRACK', 'KCOLL-KTRACK', 'full combination', 'MACRO KCOLL']
index -> [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21]
sensitivity_index -> [1, 2, 3]
sensitivity_nucleus -> ['U235', 'U238']
sensitivity_reaction -> ['SECTION CODE 104', 'SECTION CODE 33', 'SECTION CODE 52', 'PROMPT FISSION_NU', 'TOTAL FISSION_NU', 'DELAYED FISSION_NU', 'PROMPT FISSION_CHI', 'TOTAL FISSION_CHI', 'TOTAL FISSION_CHI (CONSTRAINED)', 'SCATTERING LAW 21', 'SCATTERING LAW 21 (CONSTRAINED)']
sensitivity_type -> ['CROSS SECTION', 'FISSION NU', 'FISSION CHI', 'SCATTERING TRANSFER FUNCTION']
Exemples de sélection
Pour la « démo », mais cela reflète probablement une future démarche de développement de test, on va récupérer des Browser et non les réponses directement. Cela permet notamment de sélectionner la bonne réponse pas à pas.
Sélection 1 : réponses correspondant à l’U238
[6]:
b_u238 = t4b.filter_by(sensitivity_nucleus='U238')
["{0} -> {1}".format(k, list(b_u238.available_values(k))) for k in list(b_u238.keys())]
[6]:
["response_function -> ['IFP ADJOINT WEIGHTED KEFF SENSITIVITIES']",
"response_type -> ['sensitivity']",
'response_index -> [1]',
'sensitivity_index -> [3, 1, 2]',
"sensitivity_nucleus -> ['U238']",
"sensitivity_reaction -> ['SECTION CODE 52', 'SCATTERING LAW 21', 'SCATTERING LAW 21 (CONSTRAINED)']",
"sensitivity_type -> ['CROSS SECTION', 'SCATTERING TRANSFER FUNCTION']",
'index -> [0, 1, 2]']
Sélection 2 : réponses correspondant à des sections efficaces
[7]:
b_cs = t4b.filter_by(sensitivity_type='CROSS SECTION')
["{0} -> {1}".format(k, list(b_cs.available_values(k))) for k in list(b_cs.keys())]
[7]:
["response_function -> ['IFP ADJOINT WEIGHTED KEFF SENSITIVITIES']",
"response_type -> ['sensitivity']",
'response_index -> [1]',
'sensitivity_index -> [1, 2, 3]',
"sensitivity_nucleus -> ['U235', 'U238']",
"sensitivity_reaction -> ['SECTION CODE 104', 'SECTION CODE 33', 'SECTION CODE 52']",
"sensitivity_type -> ['CROSS SECTION']",
'index -> [0, 1, 2]']
Sélection 3 : réponses correspondant au code de section efficace 52 (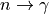 absorption)
absorption)
[8]:
b_s42 = t4b.filter_by(sensitivity_reaction='SECTION CODE 42')
WARNING browser: SECTION CODE 42 is not a valid sensitivity_reaction
[9]:
b_s52 = t4b.filter_by(sensitivity_reaction='SECTION CODE 52')
["{0} -> {1}".format(k, list(b_s52.available_values(k))) for k in list(b_s52.keys())]
[9]:
["response_function -> ['IFP ADJOINT WEIGHTED KEFF SENSITIVITIES']",
"response_type -> ['sensitivity']",
'response_index -> [1]',
'sensitivity_index -> [3]',
"sensitivity_nucleus -> ['U238']",
"sensitivity_reaction -> ['SECTION CODE 52']",
"sensitivity_type -> ['CROSS SECTION']",
'index -> [0]']
Dans ce cas on peut récupérer directement la réponse et l’utiliser grâce à la méthode select_by. Elle ne fonctionne que s’il n’y a qu’une seule réponse satisfaisant la sélection.
[10]:
r_s52 = t4b.select_by(sensitivity_reaction='SECTION CODE 52')
list(r_s52.keys())
[10]:
['response_function',
'response_type',
'response_index',
'sensitivity_index',
'sensitivity_nucleus',
'sensitivity_reaction',
'sensitivity_type',
'results',
'index']
[11]:
list(r_s52['results'].keys())
[11]:
['score', 'units', 'integrated', 'used_batches']
Dans ce cas quatre résultats sont disponibles et disponibles sous forme de Dataset.
Nombre de batches utilisés
[12]:
print('nombre de batches utilisés :', r_s52['results']['used_batches'])
ubres_s52 = r_s52['results']['used_batches']
print(ubres_s52)
nombre de batches utilisés : value: 9.100000e+01, error: 0.000000e+00, bins: OrderedDict(), type: <class 'numpy.int64'>,name: , what: sensitivity
value: 9.100000e+01, error: 0.000000e+00, bins: OrderedDict(), type: <class 'numpy.int64'>,name: , what: sensitivity
Remarque : il n’y a pas d’erreur sur le nombre de batches utilisés, le choix a été fait de l’initialiser à np.nan, ce qui ne bloque pas les tests. Il en est de même pour tous les résultats non affectés d’une erreur.
Spectre
[13]:
dssres_s52 = r_s52['results']['score']
[14]:
dssres_s52.ndim
[14]:
3
[15]:
dssres_s52.shape
[15]:
(1, 33, 1)
[16]:
dssres_s52.bins
[16]:
OrderedDict([('einc', array([], dtype=float64)),
('e',
array([1.000010e-11, 1.000000e-07, 5.400000e-07, 4.000000e-06,
8.315287e-06, 1.370959e-05, 2.260329e-05, 4.016900e-05,
6.790405e-05, 9.166088e-05, 1.486254e-04, 3.043248e-04,
4.539993e-04, 7.485183e-04, 1.234098e-03, 2.034684e-03,
3.354626e-03, 5.530844e-03, 9.118820e-03, 1.503439e-02,
2.478752e-02, 4.086771e-02, 6.737947e-02, 1.110900e-01,
1.831564e-01, 3.019738e-01, 4.978707e-01, 8.208500e-01,
1.353353e+00, 2.231302e+00, 3.678794e+00, 6.065307e+00,
1.000000e+01, 1.964033e+01])),
('mu', array([], dtype=float64))])
Comme pour les spectres ou les maillages les bins des sensibilités sont stockés dans un OrderedDict, comme dans le cas d’un spectre habituel. Seules les coordonnées sont changées, précisées par les bins.
[17]:
dssres_s52.what
[17]:
'sensitivity'
Le what par défaut est 'sensitivity'.
[18]:
dssres_s52.name='section 52'
print(dssres_s52)
shape: (1, 33, 1), dim: 3, type: <class 'numpy.ndarray'>, bins: ['einc: []', 'e: [1.000010e-11 1.000000e-07 5.400000e-07 4.000000e-06 8.315287e-06 1.370959e-05 2.260329e-05 4.016900e-05 6.790405e-05 9.166088e-05 1.486254e-04 3.043248e-04 4.539993e-04 7.485183e-04 1.234098e-03 2.034684e-03 3.354626e-03 5.530844e-03 9.118820e-03 1.503439e-02 2.478752e-02 4.086771e-02 6.737947e-02 1.110900e-01 1.831564e-01 3.019738e-01 4.978707e-01 8.208500e-01 1.353353e+00 2.231302e+00 3.678794e+00 6.065307e+00 1.000000e+01 1.964033e+01]', 'mu: []'], name: section 52, what: sensitivity
Comme dans l’exemple précédent, il est possible de réduire le spectre aux seuls bins utilisés.
[19]:
print(dssres_s52.squeeze())
shape: (33,), dim: 1, type: <class 'numpy.ndarray'>, bins: ['e: [1.000010e-11 1.000000e-07 5.400000e-07 4.000000e-06 8.315287e-06 1.370959e-05 2.260329e-05 4.016900e-05 6.790405e-05 9.166088e-05 1.486254e-04 3.043248e-04 4.539993e-04 7.485183e-04 1.234098e-03 2.034684e-03 3.354626e-03 5.530844e-03 9.118820e-03 1.503439e-02 2.478752e-02 4.086771e-02 6.737947e-02 1.110900e-01 1.831564e-01 3.019738e-01 4.978707e-01 8.208500e-01 1.353353e+00 2.231302e+00 3.678794e+00 6.065307e+00 1.000000e+01 1.964033e+01]'], name: section 52, what: sensitivity
Résultat intégré
[20]:
ires_s52 = r_s52['results']['integrated']
ires_s52.name='section 52'
ires_s52.what='sensitivity'
print(ires_s52)
shape: (1, 1, 1), dim: 3, type: <class 'numpy.ndarray'>, bins: ['einc: []', 'e: [1.000010e-11 1.964033e+01]', 'mu: []'], name: section 52, what: sensitivity
Il est également possible ici de réduire les dimensions, ce qui reviendra à ne plus avoir de bins, vu qu’il n’y en a qu’un en énergie :
[21]:
print(ires_s52.squeeze())
shape: (), dim: 0, type: <class 'numpy.ndarray'>, bins: [], name: section 52, what: sensitivity
Sélection 4 : première réponse (0) : les 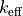
Deux types de résultats de sont disponibles :
les
qui apparaissent comme les réponses standard dans le listing de sortie de Tripoli-4, qui comportent normalement trois évaluations : KSTEP,KCOLLetKTRACKainsi que leurs corrélations et le résultat de leur combinaison, appelés ici “génériques”les
apparaissant le plus souvent en toute fin de listing, donc le discard est calculé automatiquement, de manière à en donner la meilleure estimation, appelés ici “automatiques”
“génériques”
[22]:
keffs = t4b.filter_by(response_index=0)
print(keffs.content)
[{'response_function': 'KEFFS', 'response_type': 'keff', 'response_index': 0, 'keff_estimator': 'KSTEP', 'results': {'keff': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 9.954907e-01, error: 8.759186e-04, bins: OrderedDict()
name: '', what: 'keff'
, 'correlation_keff': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 1.000000e+00, error: nan, bins: OrderedDict()
name: '', what: 'correlation'
, 'used_batches': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.int64'>
value: 9.100000e+01, error: 0.000000e+00, bins: OrderedDict()
name: '', what: 'used_batches'
}, 'index': 0}, {'response_function': 'KEFFS', 'response_type': 'keff', 'response_index': 0, 'keff_estimator': 'KCOLL', 'results': {'keff': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 9.959480e-01, error: 6.532095e-04, bins: OrderedDict()
name: '', what: 'keff'
, 'correlation_keff': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 1.000000e+00, error: nan, bins: OrderedDict()
name: '', what: 'correlation'
, 'used_batches': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.int64'>
value: 9.100000e+01, error: 0.000000e+00, bins: OrderedDict()
name: '', what: 'used_batches'
}, 'index': 1}, {'response_function': 'KEFFS', 'response_type': 'keff', 'response_index': 0, 'keff_estimator': 'KTRACK', 'results': {'keff': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 9.963401e-01, error: 5.638612e-04, bins: OrderedDict()
name: '', what: 'keff'
, 'correlation_keff': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 1.000000e+00, error: nan, bins: OrderedDict()
name: '', what: 'correlation'
, 'used_batches': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.int64'>
value: 9.100000e+01, error: 0.000000e+00, bins: OrderedDict()
name: '', what: 'used_batches'
}, 'index': 2}, {'response_function': 'KEFFS', 'response_type': 'keff', 'response_index': 0, 'keff_estimator': 'KSTEP-KCOLL', 'results': {'keff': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 9.959777e-01, error: 6.522359e-04, bins: OrderedDict()
name: '', what: 'keff'
, 'correlation_keff': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 7.799494e-01, error: nan, bins: OrderedDict()
name: '', what: 'correlation'
, 'used_batches': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.int64'>
value: 9.100000e+01, error: 0.000000e+00, bins: OrderedDict()
name: '', what: 'used_batches'
}, 'index': 3}, {'response_function': 'KEFFS', 'response_type': 'keff', 'response_index': 0, 'keff_estimator': 'KSTEP-KTRACK', 'results': {'keff': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 9.962853e-01, error: 5.619582e-04, bins: OrderedDict()
name: '', what: 'keff'
, 'correlation_keff': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 5.764322e-01, error: nan, bins: OrderedDict()
name: '', what: 'correlation'
, 'used_batches': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.int64'>
value: 9.100000e+01, error: 0.000000e+00, bins: OrderedDict()
name: '', what: 'used_batches'
}, 'index': 4}, {'response_function': 'KEFFS', 'response_type': 'keff', 'response_index': 0, 'keff_estimator': 'KCOLL-KTRACK', 'results': {'keff': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 9.962508e-01, error: 5.546109e-04, bins: OrderedDict()
name: '', what: 'keff'
, 'correlation_keff': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 7.398244e-01, error: nan, bins: OrderedDict()
name: '', what: 'correlation'
, 'used_batches': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.int64'>
value: 9.100000e+01, error: 0.000000e+00, bins: OrderedDict()
name: '', what: 'used_batches'
}, 'index': 5}, {'response_function': 'KEFFS', 'response_type': 'keff', 'response_index': 0, 'keff_estimator': 'full combination', 'results': {'keff': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 9.962563e-01, error: 5.542979e-04, bins: OrderedDict()
name: '', what: 'keff'
, 'correlation_keff': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 1.000000e+00, error: nan, bins: OrderedDict()
name: '', what: 'correlation'
, 'used_batches': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.int64'>
value: 9.100000e+01, error: 0.000000e+00, bins: OrderedDict()
name: '', what: 'used_batches'
}, 'index': 6}]
D’autres sélections sont également possibles, sans nécessité de connaître l’index de la réponse :
[23]:
keffs = t4b.filter_by(response_function='KEFFS')
print(len(keffs))
print(keffs.content)
7
[{'response_function': 'KEFFS', 'response_type': 'keff', 'response_index': 0, 'keff_estimator': 'KSTEP', 'results': {'keff': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 9.954907e-01, error: 8.759186e-04, bins: OrderedDict()
name: '', what: 'keff'
, 'correlation_keff': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 1.000000e+00, error: nan, bins: OrderedDict()
name: '', what: 'correlation'
, 'used_batches': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.int64'>
value: 9.100000e+01, error: 0.000000e+00, bins: OrderedDict()
name: '', what: 'used_batches'
}, 'index': 0}, {'response_function': 'KEFFS', 'response_type': 'keff', 'response_index': 0, 'keff_estimator': 'KCOLL', 'results': {'keff': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 9.959480e-01, error: 6.532095e-04, bins: OrderedDict()
name: '', what: 'keff'
, 'correlation_keff': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 1.000000e+00, error: nan, bins: OrderedDict()
name: '', what: 'correlation'
, 'used_batches': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.int64'>
value: 9.100000e+01, error: 0.000000e+00, bins: OrderedDict()
name: '', what: 'used_batches'
}, 'index': 1}, {'response_function': 'KEFFS', 'response_type': 'keff', 'response_index': 0, 'keff_estimator': 'KTRACK', 'results': {'keff': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 9.963401e-01, error: 5.638612e-04, bins: OrderedDict()
name: '', what: 'keff'
, 'correlation_keff': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 1.000000e+00, error: nan, bins: OrderedDict()
name: '', what: 'correlation'
, 'used_batches': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.int64'>
value: 9.100000e+01, error: 0.000000e+00, bins: OrderedDict()
name: '', what: 'used_batches'
}, 'index': 2}, {'response_function': 'KEFFS', 'response_type': 'keff', 'response_index': 0, 'keff_estimator': 'KSTEP-KCOLL', 'results': {'keff': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 9.959777e-01, error: 6.522359e-04, bins: OrderedDict()
name: '', what: 'keff'
, 'correlation_keff': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 7.799494e-01, error: nan, bins: OrderedDict()
name: '', what: 'correlation'
, 'used_batches': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.int64'>
value: 9.100000e+01, error: 0.000000e+00, bins: OrderedDict()
name: '', what: 'used_batches'
}, 'index': 3}, {'response_function': 'KEFFS', 'response_type': 'keff', 'response_index': 0, 'keff_estimator': 'KSTEP-KTRACK', 'results': {'keff': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 9.962853e-01, error: 5.619582e-04, bins: OrderedDict()
name: '', what: 'keff'
, 'correlation_keff': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 5.764322e-01, error: nan, bins: OrderedDict()
name: '', what: 'correlation'
, 'used_batches': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.int64'>
value: 9.100000e+01, error: 0.000000e+00, bins: OrderedDict()
name: '', what: 'used_batches'
}, 'index': 4}, {'response_function': 'KEFFS', 'response_type': 'keff', 'response_index': 0, 'keff_estimator': 'KCOLL-KTRACK', 'results': {'keff': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 9.962508e-01, error: 5.546109e-04, bins: OrderedDict()
name: '', what: 'keff'
, 'correlation_keff': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 7.398244e-01, error: nan, bins: OrderedDict()
name: '', what: 'correlation'
, 'used_batches': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.int64'>
value: 9.100000e+01, error: 0.000000e+00, bins: OrderedDict()
name: '', what: 'used_batches'
}, 'index': 5}, {'response_function': 'KEFFS', 'response_type': 'keff', 'response_index': 0, 'keff_estimator': 'full combination', 'results': {'keff': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 9.962563e-01, error: 5.542979e-04, bins: OrderedDict()
name: '', what: 'keff'
, 'correlation_keff': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 1.000000e+00, error: nan, bins: OrderedDict()
name: '', what: 'correlation'
, 'used_batches': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.int64'>
value: 9.100000e+01, error: 0.000000e+00, bins: OrderedDict()
name: '', what: 'used_batches'
}, 'index': 6}]
Il y a 7 disponibles comme attendu (les 3 valeurs, les 3 combinaisons deux à deux et les corrélations associées et la combinaison des trois. Il est également possible de construire des datasets à partir de chacun de ces . Il faut cependant isoler les résultats un par un :
[24]:
kstep = t4b.select_by(response_function='KEFFS', keff_estimator='KSTEP')
print(list(kstep['results'].keys()))
ds_kstep = kstep['results']['keff']
ds_kstep.name='kstep'
print(ds_kstep)
['keff', 'correlation_keff', 'used_batches']
value: 9.954907e-01, error: 8.759186e-04, bins: OrderedDict(), type: <class 'numpy.float64'>,name: kstep, what: keff
[25]:
kstep_kcoll = t4b.select_by(response_function='KEFFS', keff_estimator='KSTEP-KCOLL')
print(list(kstep_kcoll['results'].keys()))
print(kstep_kcoll['results']['keff'])
['keff', 'correlation_keff', 'used_batches']
value: 9.959777e-01, error: 6.522359e-04, bins: OrderedDict(), type: <class 'numpy.float64'>,name: , what: keff
Dans ce cas la corrélation est atteignable par :
[26]:
print(kstep_kcoll['results']['correlation_keff'])
value: 7.799494e-01, error: nan, bins: OrderedDict(), type: <class 'numpy.float64'>,name: , what: correlation
Remarque : elle n’a pas d’erreur.
“automatiques”
[27]:
keffs = t4b.filter_by(response_type='keff_auto')
print(len(keffs))
print(keffs)
4
Browser object -> Number of content items: 4, data key: 'results', available metadata keys: ['index', 'keff_estimator', 'response_type']
-> Number of globals: 6
Dans ce cas il y a un autre estimateur en plus : MACRO KCOLL. À noter également la présence du nombre de batches discarded puisqu’il est calculé par Tripoli-4.
Sélection 5 : boucle sur toutes les réponses
Il est toujours possible de faire une boucle sur toutes les réponses, dans l’ordre dans lequel elles apparaissent dans le jeu de données (par exemple pour les besoins de la non-régression).
Premier choix : boucle directe sur la liste
[28]:
for resp in lresp:
print("Response function: {0}, response type: {1}, r_index = {2}, s_index = {3}\n results keys: {4}"
.format(resp['response_function'], resp['response_type'], resp['response_index'],
resp.get('sensitivity_index', None), list(resp['results'].keys())))
Response function: KEFFS, response type: keff, r_index = 0, s_index = None
results keys: ['keff', 'correlation_keff', 'used_batches']
Response function: KEFFS, response type: keff, r_index = 0, s_index = None
results keys: ['keff', 'correlation_keff', 'used_batches']
Response function: KEFFS, response type: keff, r_index = 0, s_index = None
results keys: ['keff', 'correlation_keff', 'used_batches']
Response function: KEFFS, response type: keff, r_index = 0, s_index = None
results keys: ['keff', 'correlation_keff', 'used_batches']
Response function: KEFFS, response type: keff, r_index = 0, s_index = None
results keys: ['keff', 'correlation_keff', 'used_batches']
Response function: KEFFS, response type: keff, r_index = 0, s_index = None
results keys: ['keff', 'correlation_keff', 'used_batches']
Response function: KEFFS, response type: keff, r_index = 0, s_index = None
results keys: ['keff', 'correlation_keff', 'used_batches']
Response function: IFP ADJOINT WEIGHTED KEFF SENSITIVITIES, response type: sensitivity, r_index = 1, s_index = 1
results keys: ['score', 'units', 'integrated', 'used_batches']
Response function: IFP ADJOINT WEIGHTED KEFF SENSITIVITIES, response type: sensitivity, r_index = 1, s_index = 2
results keys: ['score', 'units', 'integrated', 'used_batches']
Response function: IFP ADJOINT WEIGHTED KEFF SENSITIVITIES, response type: sensitivity, r_index = 1, s_index = 3
results keys: ['score', 'units', 'integrated', 'used_batches']
Response function: IFP ADJOINT WEIGHTED KEFF SENSITIVITIES, response type: sensitivity, r_index = 1, s_index = 1
results keys: ['score', 'units', 'integrated', 'used_batches']
Response function: IFP ADJOINT WEIGHTED KEFF SENSITIVITIES, response type: sensitivity, r_index = 1, s_index = 2
results keys: ['score', 'units', 'integrated', 'used_batches']
Response function: IFP ADJOINT WEIGHTED KEFF SENSITIVITIES, response type: sensitivity, r_index = 1, s_index = 3
results keys: ['score', 'units', 'integrated', 'used_batches']
Response function: IFP ADJOINT WEIGHTED KEFF SENSITIVITIES, response type: sensitivity, r_index = 1, s_index = 1
results keys: ['score', 'units', 'integrated', 'used_batches']
Response function: IFP ADJOINT WEIGHTED KEFF SENSITIVITIES, response type: sensitivity, r_index = 1, s_index = 2
results keys: ['score', 'units', 'integrated', 'used_batches']
Response function: IFP ADJOINT WEIGHTED KEFF SENSITIVITIES, response type: sensitivity, r_index = 1, s_index = 3
results keys: ['score', 'units', 'integrated', 'used_batches']
Response function: IFP ADJOINT WEIGHTED KEFF SENSITIVITIES, response type: sensitivity, r_index = 1, s_index = 1
results keys: ['score', 'units', 'integrated', 'used_batches']
Response function: IFP ADJOINT WEIGHTED KEFF SENSITIVITIES, response type: sensitivity, r_index = 1, s_index = 2
results keys: ['score', 'units', 'integrated', 'used_batches']
Dans ce cas les réponses sont déjà « aplaties »… mais le gros avantage est que les métadonnées sont accessibles pour chaque réponse (même les communes), il n’y a donc pas de perte d’information.
Deuxième choix : boucle grâce au Browser (boucle sur le 'response_index')
[29]:
val_rindex = list(t4b.available_values('response_index'))
val_rindex
[29]:
[0, 1]
[30]:
for ind in val_rindex:
b_ind = t4b.filter_by(response_index=ind)
print("Nombre de 'scores' par réponse =", b_ind)
for resp in b_ind.content:
print("Response function = {0}, sensitivity type = {1}, sensitivity index = {2}"
.format(resp['response_function'], resp.get('sensitivity_type', None),
resp.get('sensitivity_index', None)))
Nombre de 'scores' par réponse = Browser object -> Number of content items: 7, data key: 'results', available metadata keys: ['index', 'keff_estimator', 'response_function', 'response_index', 'response_type']
-> Number of globals: 6
Response function = KEFFS, sensitivity type = None, sensitivity index = None
Response function = KEFFS, sensitivity type = None, sensitivity index = None
Response function = KEFFS, sensitivity type = None, sensitivity index = None
Response function = KEFFS, sensitivity type = None, sensitivity index = None
Response function = KEFFS, sensitivity type = None, sensitivity index = None
Response function = KEFFS, sensitivity type = None, sensitivity index = None
Response function = KEFFS, sensitivity type = None, sensitivity index = None
Nombre de 'scores' par réponse = Browser object -> Number of content items: 11, data key: 'results', available metadata keys: ['index', 'response_function', 'response_index', 'response_type', 'sensitivity_index', 'sensitivity_nucleus', 'sensitivity_reaction', 'sensitivity_type']
-> Number of globals: 6
Response function = IFP ADJOINT WEIGHTED KEFF SENSITIVITIES, sensitivity type = CROSS SECTION, sensitivity index = 1
Response function = IFP ADJOINT WEIGHTED KEFF SENSITIVITIES, sensitivity type = CROSS SECTION, sensitivity index = 2
Response function = IFP ADJOINT WEIGHTED KEFF SENSITIVITIES, sensitivity type = CROSS SECTION, sensitivity index = 3
Response function = IFP ADJOINT WEIGHTED KEFF SENSITIVITIES, sensitivity type = FISSION NU, sensitivity index = 1
Response function = IFP ADJOINT WEIGHTED KEFF SENSITIVITIES, sensitivity type = FISSION NU, sensitivity index = 2
Response function = IFP ADJOINT WEIGHTED KEFF SENSITIVITIES, sensitivity type = FISSION NU, sensitivity index = 3
Response function = IFP ADJOINT WEIGHTED KEFF SENSITIVITIES, sensitivity type = FISSION CHI, sensitivity index = 1
Response function = IFP ADJOINT WEIGHTED KEFF SENSITIVITIES, sensitivity type = FISSION CHI, sensitivity index = 2
Response function = IFP ADJOINT WEIGHTED KEFF SENSITIVITIES, sensitivity type = FISSION CHI, sensitivity index = 3
Response function = IFP ADJOINT WEIGHTED KEFF SENSITIVITIES, sensitivity type = SCATTERING TRANSFER FUNCTION, sensitivity index = 1
Response function = IFP ADJOINT WEIGHTED KEFF SENSITIVITIES, sensitivity type = SCATTERING TRANSFER FUNCTION, sensitivity index = 2
Dans le cas présent on obtient tous les résultats formatés de la même manière dans le listing de sortie de Tripoli-4, les “automatiques” n’y sont donc pas. Ils peuvent cependant être également obtenus dans la boucle, à condition de boucler sur 'index' au lieu de 'response_index' :
[31]:
val_index = list(t4b.available_values('index'))
print('index :', val_index)
for ind in val_index:
b_ind = t4b.filter_by(index=ind)
print("Nombre de 'scores' par réponse =", b_ind)
for resp in b_ind.content:
print("Response function = {0}, response type = {1}, sensitivity type = {2}, sensitivity index = {3}"
.format(resp.get('response_function', None), resp['response_type'],
resp.get('sensitivity_type', None), resp.get('sensitivity_index', None)))
if resp.get('response_function') is None:
print(resp)
index : [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21]
Nombre de 'scores' par réponse = Browser object -> Number of content items: 1, data key: 'results', available metadata keys: ['index', 'keff_estimator', 'response_function', 'response_index', 'response_type']
-> Number of globals: 6
Response function = KEFFS, response type = keff, sensitivity type = None, sensitivity index = None
Nombre de 'scores' par réponse = Browser object -> Number of content items: 1, data key: 'results', available metadata keys: ['index', 'keff_estimator', 'response_function', 'response_index', 'response_type']
-> Number of globals: 6
Response function = KEFFS, response type = keff, sensitivity type = None, sensitivity index = None
Nombre de 'scores' par réponse = Browser object -> Number of content items: 1, data key: 'results', available metadata keys: ['index', 'keff_estimator', 'response_function', 'response_index', 'response_type']
-> Number of globals: 6
Response function = KEFFS, response type = keff, sensitivity type = None, sensitivity index = None
Nombre de 'scores' par réponse = Browser object -> Number of content items: 1, data key: 'results', available metadata keys: ['index', 'keff_estimator', 'response_function', 'response_index', 'response_type']
-> Number of globals: 6
Response function = KEFFS, response type = keff, sensitivity type = None, sensitivity index = None
Nombre de 'scores' par réponse = Browser object -> Number of content items: 1, data key: 'results', available metadata keys: ['index', 'keff_estimator', 'response_function', 'response_index', 'response_type']
-> Number of globals: 6
Response function = KEFFS, response type = keff, sensitivity type = None, sensitivity index = None
Nombre de 'scores' par réponse = Browser object -> Number of content items: 1, data key: 'results', available metadata keys: ['index', 'keff_estimator', 'response_function', 'response_index', 'response_type']
-> Number of globals: 6
Response function = KEFFS, response type = keff, sensitivity type = None, sensitivity index = None
Nombre de 'scores' par réponse = Browser object -> Number of content items: 1, data key: 'results', available metadata keys: ['index', 'keff_estimator', 'response_function', 'response_index', 'response_type']
-> Number of globals: 6
Response function = KEFFS, response type = keff, sensitivity type = None, sensitivity index = None
Nombre de 'scores' par réponse = Browser object -> Number of content items: 1, data key: 'results', available metadata keys: ['index', 'response_function', 'response_index', 'response_type', 'sensitivity_index', 'sensitivity_nucleus', 'sensitivity_reaction', 'sensitivity_type']
-> Number of globals: 6
Response function = IFP ADJOINT WEIGHTED KEFF SENSITIVITIES, response type = sensitivity, sensitivity type = CROSS SECTION, sensitivity index = 1
Nombre de 'scores' par réponse = Browser object -> Number of content items: 1, data key: 'results', available metadata keys: ['index', 'response_function', 'response_index', 'response_type', 'sensitivity_index', 'sensitivity_nucleus', 'sensitivity_reaction', 'sensitivity_type']
-> Number of globals: 6
Response function = IFP ADJOINT WEIGHTED KEFF SENSITIVITIES, response type = sensitivity, sensitivity type = CROSS SECTION, sensitivity index = 2
Nombre de 'scores' par réponse = Browser object -> Number of content items: 1, data key: 'results', available metadata keys: ['index', 'response_function', 'response_index', 'response_type', 'sensitivity_index', 'sensitivity_nucleus', 'sensitivity_reaction', 'sensitivity_type']
-> Number of globals: 6
Response function = IFP ADJOINT WEIGHTED KEFF SENSITIVITIES, response type = sensitivity, sensitivity type = CROSS SECTION, sensitivity index = 3
Nombre de 'scores' par réponse = Browser object -> Number of content items: 1, data key: 'results', available metadata keys: ['index', 'response_function', 'response_index', 'response_type', 'sensitivity_index', 'sensitivity_nucleus', 'sensitivity_reaction', 'sensitivity_type']
-> Number of globals: 6
Response function = IFP ADJOINT WEIGHTED KEFF SENSITIVITIES, response type = sensitivity, sensitivity type = FISSION NU, sensitivity index = 1
Nombre de 'scores' par réponse = Browser object -> Number of content items: 1, data key: 'results', available metadata keys: ['index', 'response_function', 'response_index', 'response_type', 'sensitivity_index', 'sensitivity_nucleus', 'sensitivity_reaction', 'sensitivity_type']
-> Number of globals: 6
Response function = IFP ADJOINT WEIGHTED KEFF SENSITIVITIES, response type = sensitivity, sensitivity type = FISSION NU, sensitivity index = 2
Nombre de 'scores' par réponse = Browser object -> Number of content items: 1, data key: 'results', available metadata keys: ['index', 'response_function', 'response_index', 'response_type', 'sensitivity_index', 'sensitivity_nucleus', 'sensitivity_reaction', 'sensitivity_type']
-> Number of globals: 6
Response function = IFP ADJOINT WEIGHTED KEFF SENSITIVITIES, response type = sensitivity, sensitivity type = FISSION NU, sensitivity index = 3
Nombre de 'scores' par réponse = Browser object -> Number of content items: 1, data key: 'results', available metadata keys: ['index', 'response_function', 'response_index', 'response_type', 'sensitivity_index', 'sensitivity_nucleus', 'sensitivity_reaction', 'sensitivity_type']
-> Number of globals: 6
Response function = IFP ADJOINT WEIGHTED KEFF SENSITIVITIES, response type = sensitivity, sensitivity type = FISSION CHI, sensitivity index = 1
Nombre de 'scores' par réponse = Browser object -> Number of content items: 1, data key: 'results', available metadata keys: ['index', 'response_function', 'response_index', 'response_type', 'sensitivity_index', 'sensitivity_nucleus', 'sensitivity_reaction', 'sensitivity_type']
-> Number of globals: 6
Response function = IFP ADJOINT WEIGHTED KEFF SENSITIVITIES, response type = sensitivity, sensitivity type = FISSION CHI, sensitivity index = 2
Nombre de 'scores' par réponse = Browser object -> Number of content items: 1, data key: 'results', available metadata keys: ['index', 'response_function', 'response_index', 'response_type', 'sensitivity_index', 'sensitivity_nucleus', 'sensitivity_reaction', 'sensitivity_type']
-> Number of globals: 6
Response function = IFP ADJOINT WEIGHTED KEFF SENSITIVITIES, response type = sensitivity, sensitivity type = FISSION CHI, sensitivity index = 3
Nombre de 'scores' par réponse = Browser object -> Number of content items: 1, data key: 'results', available metadata keys: ['index', 'response_function', 'response_index', 'response_type', 'sensitivity_index', 'sensitivity_nucleus', 'sensitivity_reaction', 'sensitivity_type']
-> Number of globals: 6
Response function = IFP ADJOINT WEIGHTED KEFF SENSITIVITIES, response type = sensitivity, sensitivity type = SCATTERING TRANSFER FUNCTION, sensitivity index = 1
Nombre de 'scores' par réponse = Browser object -> Number of content items: 1, data key: 'results', available metadata keys: ['index', 'response_function', 'response_index', 'response_type', 'sensitivity_index', 'sensitivity_nucleus', 'sensitivity_reaction', 'sensitivity_type']
-> Number of globals: 6
Response function = IFP ADJOINT WEIGHTED KEFF SENSITIVITIES, response type = sensitivity, sensitivity type = SCATTERING TRANSFER FUNCTION, sensitivity index = 2
Nombre de 'scores' par réponse = Browser object -> Number of content items: 1, data key: 'results', available metadata keys: ['index', 'keff_estimator', 'response_type']
-> Number of globals: 6
Response function = None, response type = keff_auto, sensitivity type = None, sensitivity index = None
{'response_type': 'keff_auto', 'keff_estimator': 'KSTEP', 'results': {'keff': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 9.956131e-01, error: 8.121986e-04, bins: OrderedDict()
name: '', what: 'keff'
, 'used_batches': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.int64'>
value: 1.150000e+02, error: 0.000000e+00, bins: OrderedDict()
name: '', what: 'used_batches'
, 'discarded_batches': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.int64'>
value: 5.000000e+00, error: 0.000000e+00, bins: OrderedDict()
name: '', what: 'discarded_batches'
}, 'index': 0}
Nombre de 'scores' par réponse = Browser object -> Number of content items: 1, data key: 'results', available metadata keys: ['index', 'keff_estimator', 'response_type']
-> Number of globals: 6
Response function = None, response type = keff_auto, sensitivity type = None, sensitivity index = None
{'response_type': 'keff_auto', 'keff_estimator': 'KCOLL', 'results': {'keff': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 9.957839e-01, error: 6.040021e-04, bins: OrderedDict()
name: '', what: 'keff'
, 'used_batches': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.int64'>
value: 1.140000e+02, error: 0.000000e+00, bins: OrderedDict()
name: '', what: 'used_batches'
, 'discarded_batches': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.int64'>
value: 6.000000e+00, error: 0.000000e+00, bins: OrderedDict()
name: '', what: 'discarded_batches'
}, 'index': 0}
Nombre de 'scores' par réponse = Browser object -> Number of content items: 1, data key: 'results', available metadata keys: ['index', 'keff_estimator', 'response_type']
-> Number of globals: 6
Response function = None, response type = keff_auto, sensitivity type = None, sensitivity index = None
{'response_type': 'keff_auto', 'keff_estimator': 'KTRACK', 'results': {'keff': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 9.961751e-01, error: 4.986042e-04, bins: OrderedDict()
name: '', what: 'keff'
, 'used_batches': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.int64'>
value: 1.150000e+02, error: 0.000000e+00, bins: OrderedDict()
name: '', what: 'used_batches'
, 'discarded_batches': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.int64'>
value: 5.000000e+00, error: 0.000000e+00, bins: OrderedDict()
name: '', what: 'discarded_batches'
}, 'index': 0}
Nombre de 'scores' par réponse = Browser object -> Number of content items: 1, data key: 'results', available metadata keys: ['index', 'keff_estimator', 'response_type']
-> Number of globals: 6
Response function = None, response type = keff_auto, sensitivity type = None, sensitivity index = None
{'response_type': 'keff_auto', 'keff_estimator': 'MACRO KCOLL', 'results': {'keff': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 9.957877e-01, error: 5.886514e-04, bins: OrderedDict()
name: '', what: 'keff'
, 'used_batches': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.int64'>
value: 1.150000e+02, error: 0.000000e+00, bins: OrderedDict()
name: '', what: 'used_batches'
, 'discarded_batches': class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.int64'>
value: 5.000000e+00, error: 0.000000e+00, bins: OrderedDict()
name: '', what: 'discarded_batches'
}, 'index': 0}
Exemples de comparaison de
On va faire différents tests pour comparer les valeurs de :
TestEqualqui vérifie que les datasets sont égaux (ce test est plutôt prévu pour des valeurs entières comme les nombres de batches)TestApproxEqualqui vérifie que les datasets sont approximativement égaux (pertinent pour lesfloatpour lesquels on n’a pas d’erreur associée, les corrélations de par exempleTestStudentdans le cas où l’on veut prendre en compte les erreurs sur les valeurs
Pour tous ces tests il faut définir une référence, qui sera en fait le premier dataset donné.
Pour les exemples ci-dessous on choisit les des réponses (response_function='KEFFS'). On prendra comme référence le KSTEP pour plus de facilités car c’est le premier résultat donné.
[32]:
sb = t4b.filter_by(response_function='KEFFS')
print('estimators values:', list(sb.available_values('keff_estimator')))
dsets = []
for keff in sb.content:
dsets.append(keff['results']['keff'])
dsets[-1].name=keff['keff_estimator']
print(dsets)
estimators values: ['KSTEP', 'KCOLL', 'KTRACK', 'KSTEP-KCOLL', 'KSTEP-KTRACK', 'KCOLL-KTRACK', 'full combination']
[class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 9.954907e-01, error: 8.759186e-04, bins: OrderedDict()
name: 'KSTEP', what: 'keff'
, class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 9.959480e-01, error: 6.532095e-04, bins: OrderedDict()
name: 'KCOLL', what: 'keff'
, class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 9.963401e-01, error: 5.638612e-04, bins: OrderedDict()
name: 'KTRACK', what: 'keff'
, class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 9.959777e-01, error: 6.522359e-04, bins: OrderedDict()
name: 'KSTEP-KCOLL', what: 'keff'
, class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 9.962853e-01, error: 5.619582e-04, bins: OrderedDict()
name: 'KSTEP-KTRACK', what: 'keff'
, class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 9.962508e-01, error: 5.546109e-04, bins: OrderedDict()
name: 'KCOLL-KTRACK', what: 'keff'
, class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.float64'>
value: 9.962563e-01, error: 5.542979e-04, bins: OrderedDict()
name: 'full combination', what: 'keff'
]
On importe les tests et la possibilité d’en faire des représentations.
[33]:
from valjean.gavroche.test import TestEqual, TestApproxEqual
from valjean.gavroche.stat_tests.student import TestStudent
from valjean.javert.representation import FullRepresenter
from valjean.javert.rst import RstFormatter
from valjean.javert.mpl import MplPlot
from valjean.javert.verbosity import Verbosity
frepr = FullRepresenter()
rstformat = RstFormatter()
[34]:
teq_res = TestEqual(*dsets, name='TestEqual', description='Test le TestEqual sur les keff').evaluate()
print(bool(teq_res)) # expected: False
False
[35]:
eqrepr = frepr(teq_res, verbosity=Verbosity.FULL_DETAILS) # il s'agit d'une liste de templates
print(eqrepr, len(eqrepr))
eqrst = rstformat.template(eqrepr[0])
print(eqrst)
[class: <class 'valjean.javert.templates.TableTemplate'>
headers: ['KSTEP', 'KCOLL', 'equal(KCOLL)?', 'KTRACK', 'equal(KTRACK)?', 'KSTEP-KCOLL', 'equal(KSTEP-KCOLL)?', 'KSTEP-KTRACK', 'equal(KSTEP-KTRACK)?', 'KCOLL-KTRACK', 'equal(KCOLL-KTRACK)?', 'full combination', 'equal(full combination)?']
KSTEP: 0.9954907
KCOLL: 0.995948
equal(KCOLL)?: False
KTRACK: 0.9963401
equal(KTRACK)?: False
KSTEP-KCOLL: 0.9959777
equal(KSTEP-KCOLL)?: False
KSTEP-KTRACK: 0.9962853
equal(KSTEP-KTRACK)?: False
KCOLL-KTRACK: 0.9962508
equal(KCOLL-KTRACK)?: False
full combination: 0.9962563
equal(full combination)?: False
highlights: [array(False), array(False), True, array(False), True, array(False), True, array(False), True, array(False), True, array(False), True]] 1
.. role:: hl
.. table::
:widths: auto
=========== =========== ============= =========== ============== =========== =================== ============ ==================== ============ ==================== ================ ========================
KSTEP KCOLL equal(KCOLL)? KTRACK equal(KTRACK)? KSTEP-KCOLL equal(KSTEP-KCOLL)? KSTEP-KTRACK equal(KSTEP-KTRACK)? KCOLL-KTRACK equal(KCOLL-KTRACK)? full combination equal(full combination)?
=========== =========== ============= =========== ============== =========== =================== ============ ==================== ============ ==================== ================ ========================
0.995491 0.995948 :hl:`False` 0.99634 :hl:`False` 0.995978 :hl:`False` 0.996285 :hl:`False` 0.996251 :hl:`False` 0.996256 :hl:`False`
=========== =========== ============= =========== ============== =========== =================== ============ ==================== ============ ==================== ================ ========================
[36]:
tstud_res = TestStudent(*dsets, name='TestStudent', description='Test le TestStudent sur les keff').evaluate()
print(bool(tstud_res))
True
[37]:
studrepr = frepr(tstud_res, verbosity=Verbosity.FULL_DETAILS) # il s'agit d'une liste de templates
print(len(studrepr), [type(t) for t in studrepr])
studrst = rstformat.template(studrepr[0])
print(studrst)
1 [<class 'valjean.javert.templates.TableTemplate'>]
.. role:: hl
.. table::
:widths: auto
=========== =========== =========== =========== =========== =============== =========== =========== =========== ================ ============== ============== ============== ===================== =============== =============== =============== ====================== =============== =============== =============== ====================== =================== =================== =================== ==========================
v(KSTEP) σ(KSTEP) v(KCOLL) σ(KCOLL) t(KCOLL) Student(KCOLL)? v(KTRACK) σ(KTRACK) t(KTRACK) Student(KTRACK)? v(KSTEP-KCOLL) σ(KSTEP-KCOLL) t(KSTEP-KCOLL) Student(KSTEP-KCOLL)? v(KSTEP-KTRACK) σ(KSTEP-KTRACK) t(KSTEP-KTRACK) Student(KSTEP-KTRACK)? v(KCOLL-KTRACK) σ(KCOLL-KTRACK) t(KCOLL-KTRACK) Student(KCOLL-KTRACK)? v(full combination) σ(full combination) t(full combination) Student(full combination)?
=========== =========== =========== =========== =========== =============== =========== =========== =========== ================ ============== ============== ============== ===================== =============== =============== =============== ====================== =============== =============== =============== ====================== =================== =================== =================== ==========================
0.995491 0.000875919 0.995948 0.00065321 -0.418518 True 0.99634 0.000563861 -0.815385 True 0.995978 0.000652236 -0.445937 True 0.996285 0.000561958 -0.763534 True 0.996251 0.000554611 -0.733165 True 0.996256 0.000554298 -0.738589 True
=========== =========== =========== =========== =========== =============== =========== =========== =========== ================ ============== ============== ============== ===================== =============== =============== =============== ====================== =============== =============== =============== ====================== =================== =================== =================== ==========================
Il est possible d’avoir une représentation de ce test plus lisible en créant deux Dataset : l’un contenant tous ces résultats, l’autre, qui servira de référence, le KSTEP autant de fois que d’éléments dans le premier. Dans ce cas la représentation permettra également d’avoir une représentation graphique.
Pour les bins, le plus simple est de donner les noms des estimateurs, actuellement stocké comme 'name'.
Cette forme permet également de comparer ces mêmes valeurs pour différentes versions de Tripoli-4 par exemple.
[38]:
from collections import OrderedDict
import numpy as np
from valjean.eponine.dataset import Dataset
[39]:
dset_test = Dataset(value=np.array([k.value for k in dsets]),
error=np.array([k.error for k in dsets]),
bins=OrderedDict([('estimator', np.array([k.name for k in dsets]))]),
name='Test', what='keff')
print(dset_test)
shape: (7,), dim: 1, type: <class 'numpy.ndarray'>, bins: ["estimator: ['KSTEP' 'KCOLL' 'KTRACK' 'KSTEP-KCOLL' 'KSTEP-KTRACK' 'KCOLL-KTRACK' 'full combination']"], name: Test, what: keff
On fait maintenant le Dataset de référence.
ATTENTION
Pour pouvoir comparer des Dataset il faut qu’ils aient les mêmes bins. La référence (qui ne contient que KSTEP) doit donc avoir tous les estimateurs dans les bins (les valeurs étant bien sûr celles du KSTEP).
[40]:
dset_ref = Dataset(value=np.array([ds_kstep.value for _ in dsets]),
error=np.array([ds_kstep.error for _ in dsets]),
bins=OrderedDict([('estimator', np.array([k.name for k in dsets]))]),
name='Ref (KSTEP)', what='keff')
print(dset_ref)
shape: (7,), dim: 1, type: <class 'numpy.ndarray'>, bins: ["estimator: ['KSTEP' 'KCOLL' 'KTRACK' 'KSTEP-KCOLL' 'KSTEP-KTRACK' 'KCOLL-KTRACK' 'full combination']"], name: Ref (KSTEP), what: keff
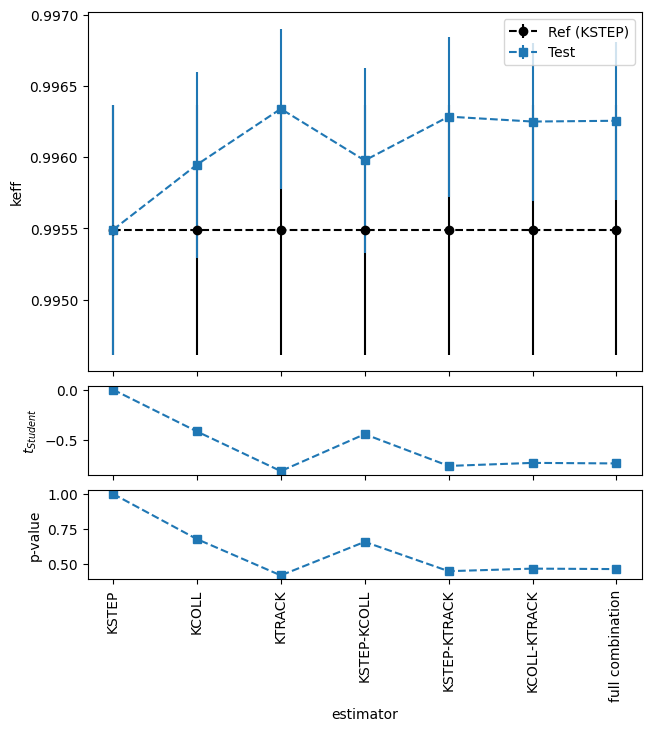
Représentation avec le TestStudent
[41]:
tstudRT_res = TestStudent(dset_ref, dset_test, name='TestStudent', description='Test le TestStudent sur les keff').evaluate()
print(bool(tstudRT_res))
True
[42]:
studRTtemp = frepr(tstudRT_res, verbosity=Verbosity.FULL_DETAILS) # il s'agit d'une liste de templates
print(len(studRTtemp), [type(t) for t in studRTtemp])
studRTrst = rstformat.template(studRTtemp[1])
print(studRTrst)
mpl = MplPlot(studRTtemp[0]).draw()
2 [<class 'valjean.javert.templates.PlotTemplate'>, <class 'valjean.javert.templates.TableTemplate'>]
.. role:: hl
.. table::
:widths: auto
================ ============== ============== =========== =========== =========== ========
estimator v(Ref (KSTEP)) σ(Ref (KSTEP)) v(Test) σ(Test) t Student?
================ ============== ============== =========== =========== =========== ========
KSTEP 0.995491 0.000875919 0.995491 0.000875919 0 True
KCOLL 0.995491 0.000875919 0.995948 0.00065321 -0.418518 True
KTRACK 0.995491 0.000875919 0.99634 0.000563861 -0.815385 True
KSTEP-KCOLL 0.995491 0.000875919 0.995978 0.000652236 -0.445937 True
KSTEP-KTRACK 0.995491 0.000875919 0.996285 0.000561958 -0.763534 True
KCOLL-KTRACK 0.995491 0.000875919 0.996251 0.000554611 -0.733165 True
full combination 0.995491 0.000875919 0.996256 0.000554298 -0.738589 True
================ ============== ============== =========== =========== =========== ========
Représentation avec le TestApproxEqual
[43]:
dscorr = []
for keff in sb.content:
dscorr.append(keff['results']['correlation_keff'])
dscorr[-1].name=keff['keff_estimator']
dscorr_test = Dataset(value=np.array([k.value for k in dscorr]),
error=np.array([k.error for k in dscorr]),
bins=OrderedDict([('estimator', np.array([k.name for k in dscorr]))]),
name='Test', what='correlation')
dscorr_kstep = kstep['results']['correlation_keff']
dscorr_kstep.name=kstep['keff_estimator']
dscorr_ref = Dataset(value=np.array([dscorr_kstep.value for _ in dscorr]),
error=np.array([dscorr_kstep.error for _ in dscorr]),
bins=OrderedDict([('estimator', np.array([k.name for k in dscorr]))]),
name='Ref (KSTEP)', what='correlation')
taeqRT_res = TestApproxEqual(
dscorr_ref, dscorr_test, name='TestApproxEqual',
description='Test le TestApproxEqual sur les correlations entre estimations de keff').evaluate()
print(bool(taeqRT_res))
aeqRTtemp = frepr(taeqRT_res, verbosity=Verbosity.FULL_DETAILS) # il s'agit d'une liste de templates
print(len(aeqRTtemp), [type(t) for t in aeqRTtemp])
aeqRTrst = rstformat.template(aeqRTtemp[1])
print(aeqRTrst)
mpl = MplPlot(aeqRTtemp[0]).draw()
False
2 [<class 'valjean.javert.templates.PlotTemplate'>, <class 'valjean.javert.templates.TableTemplate'>]
.. role:: hl
.. table::
:widths: auto
================ =========== =========== =============
estimator Ref (KSTEP) Test approx equal?
================ =========== =========== =============
KSTEP 1 1 True
KCOLL 1 1 True
KTRACK 1 1 True
KSTEP-KCOLL 1 0.779949 :hl:`False`
KSTEP-KTRACK 1 0.576432 :hl:`False`
KCOLL-KTRACK 1 0.739824 :hl:`False`
full combination 1 1 True
================ =========== =========== =============

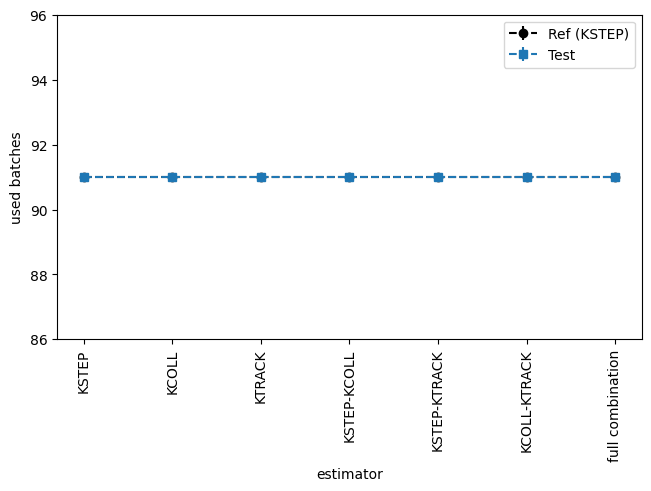
Représentation avec TestEqual
[44]:
dsub = []
for keff in sb.content:
dsub.append(keff['results']['used_batches'])
dsub[-1].name=keff['keff_estimator'] #, what='used batches'))
dsub_test = Dataset(value=np.array([k.value for k in dsub]),
error=np.array([k.error for k in dsub]),
bins=OrderedDict([('estimator', np.array([k.name for k in dsub]))]),
name='Test', what='used batches')
dsub_kstep = kstep['results']['used_batches']
dsub_kstep.name=kstep['keff_estimator'] # , what='used batches')
dsub_ref = Dataset(value=np.array([dsub_kstep.value for _ in dsub]),
error=np.array([dsub_kstep.error for _ in dsub]),
bins=OrderedDict([('estimator', np.array([k.name for k in dsub]))]),
name='Ref (KSTEP)', what='used batches')
print(dsub)
teqRT_res = TestEqual(
dsub_ref, dsub_test, name='TestEqual',
description='Test le TestEqual sur les batches utilisés pour les estimations de keff').evaluate()
print(bool(teqRT_res))
eqRTtemp = frepr(teqRT_res, verbosity=Verbosity.FULL_DETAILS) # il s'agit d'une liste de templates
print(len(eqRTtemp), [type(t) for t in eqRTtemp])
eqRTrst = rstformat.template(eqRTtemp[1])
print(eqRTrst)
mpl = MplPlot(eqRTtemp[0]).draw()
[class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.int64'>
value: 9.100000e+01, error: 0.000000e+00, bins: OrderedDict()
name: 'KSTEP', what: 'used_batches'
, class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.int64'>
value: 9.100000e+01, error: 0.000000e+00, bins: OrderedDict()
name: 'KCOLL', what: 'used_batches'
, class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.int64'>
value: 9.100000e+01, error: 0.000000e+00, bins: OrderedDict()
name: 'KTRACK', what: 'used_batches'
, class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.int64'>
value: 9.100000e+01, error: 0.000000e+00, bins: OrderedDict()
name: 'KSTEP-KCOLL', what: 'used_batches'
, class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.int64'>
value: 9.100000e+01, error: 0.000000e+00, bins: OrderedDict()
name: 'KSTEP-KTRACK', what: 'used_batches'
, class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.int64'>
value: 9.100000e+01, error: 0.000000e+00, bins: OrderedDict()
name: 'KCOLL-KTRACK', what: 'used_batches'
, class: <class 'valjean.eponine.dataset.Dataset'>, data type: <class 'numpy.int64'>
value: 9.100000e+01, error: 0.000000e+00, bins: OrderedDict()
name: 'full combination', what: 'used_batches'
]
True
2 [<class 'valjean.javert.templates.PlotTemplate'>, <class 'valjean.javert.templates.TableTemplate'>]
.. role:: hl
.. table::
:widths: auto
================ =========== ==== ======
estimator Ref (KSTEP) Test equal?
================ =========== ==== ======
KSTEP 91 91 True
KCOLL 91 91 True
KTRACK 91 91 True
KSTEP-KCOLL 91 91 True
KSTEP-KTRACK 91 91 True
KCOLL-KTRACK 91 91 True
full combination 91 91 True
================ =========== ==== ======
Si on veut comparer les résultats à d’autres obtenus à partir d’une autre version de Tripoli-4 par exemple, on peut faire un dataset unique et le mettre dans un test.