Godiva : analyse de 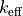
Le jeu de données utilisé est : heu-met-fast-001-godiva.
Les résultats à analyser sont les calculés par Tripoli-4.
Parsing du jeu de données et exploration des résultats
[1]:
from valjean.eponine.tripoli4.parse import Parser
# scan du jeu de données
t4p = Parser('heu-met-fast-001-godiva.res')
# parsing du dernier batch (par défaut, index=-1)
t4res = t4p.parse_from_index()
# clefs disponibles dans le dictionnaire de résultats
list(t4res.res.keys())
INFO parse: Parsing heu-met-fast-001-godiva.res
INFO parse: Successful scan in 0.036787 s
INFO parse: Successful parsing in 0.107602 s
[1]:
['list_responses', 'keff_auto', 'batch_data', 'run_data']
Pour manipuler plus aisément les réponses de Tripoli-4 et en particulier les sélectionner on utilise un objet Browser.
[2]:
t4b = t4res.to_browser()
print(t4b)
Browser object -> Number of content items: 18, data key: 'results', available metadata keys: ['index', 'keff_estimator', 'response_function', 'response_index', 'response_type']
-> Number of globals: 6
Accès aux paramètres globaux du résultat :
[3]:
from pprint import pprint
pprint(t4b.globals)
{'batch_number': 2100,
'edition_batch_number': 2100,
'mean_weight_leak': {'score': 573.9424,
'sigma': 0.3446137,
'sigma%': 0.06004325},
'name': '',
'simulation_time': 30,
'source_intensity': 12.56637}
Le contenu (soit les réponses) est caractérisé par des mots-clefs - valeurs :
[4]:
for k in list(t4b.keys()):
print("{0} -> {1}".format(k, list(t4b.available_values(k))))
response_function -> ['PRODUCTION', 'ABSORPTION', 'LEAKAGE', 'LEAKAGE_INSIDE', 'NXN EXCESS', 'FLUX TOTAL', 'ENERGY LEAKAGE', 'KEFFS']
response_type -> ['generic', 'keff', 'keff_auto']
response_index -> [0, 1, 2, 3, 4, 5, 6, 7]
index -> [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17]
keff_estimator -> ['KSTEP', 'KCOLL', 'KTRACK', 'KSTEP-KCOLL', 'KSTEP-KTRACK', 'KCOLL-KTRACK', 'full combination', 'MACRO KCOLL']
La sélection de la réponse se fait grâce aux mots-clefs - valeurs ci-dessus par les méthodes
filter_by→ sous-Browsercorrespondant à la sélectionselect_by→ réponse unique correspondant à la sélection (exception s’il n’y a pas de correspondance ou si plusieurs réponses correspondent)
Sélection des
Deux types de résultats de sont disponibles :
les
qui apparaissent comme les réponses standard dans le listing de sortie de Tripoli-4, qui comportent normalement trois évaluations : KSTEP,KCOLLetKTRACKainsi que leurs corrélations et le résultat de leur combinaison, appelés ici “génériques”les
apparaissant le plus souvent en toute fin de listing, donc le discard est calculé automatiquement, de manière à en donner la meilleure estimation, appelés ici “automatiques”
“génériques”
[5]:
keffs = t4b.filter_by(response_function='KEFFS')
print(len(keffs))
7
Il y a 7 disponibles comme attendu (les 3 valeurs, les 3 combinaisons deux à deux et les corrélations associées et la combinaison des trois. Pour en connaître la liste précise et pouvoir les isoler le plus simple est d’utiliser la clef 'keff_estimator' :
[6]:
pprint(list(keffs.available_values('keff_estimator')))
['KSTEP',
'KCOLL',
'KTRACK',
'KSTEP-KCOLL',
'KSTEP-KTRACK',
'KCOLL-KTRACK',
'full combination']
La sélection des avec les clefs 'response_function' et 'keff_estimator' donnant un unique résultat il est possible d’utiliser select_by pour le récupérer directement.
[7]:
kstep = t4b.select_by(response_function='KEFFS', keff_estimator='KSTEP')
print(list(kstep['results'].keys()))
ds_kstep = kstep['results']['keff']
ds_kstep.name='kstep' # name is '' by default
print(ds_kstep)
['keff', 'correlation_keff', 'used_batches']
value: 9.978572e-01, error: 8.598928e-04, bins: OrderedDict(), type: <class 'numpy.float64'>,name: kstep, what: keff
[8]:
kstep_kcoll = t4b.select_by(response_function='KEFFS', keff_estimator='KSTEP-KCOLL')
print(list(kstep_kcoll['results'].keys()))
print(kstep_kcoll['results']['keff'])
['keff', 'correlation_keff', 'used_batches']
value: 9.967598e-01, error: 6.801727e-04, bins: OrderedDict(), type: <class 'numpy.float64'>,name: , what: keff
Pour obtenir la corrélation :
[9]:
print(kstep_kcoll['results']['correlation_keff'])
value: 7.913696e-01, error: nan, bins: OrderedDict(), type: <class 'numpy.float64'>,name: , what: correlation
Remarque : elle n’a pas d’erreur.
“automatiques”
[10]:
keffs = t4b.filter_by(response_type='keff_auto')
print(len(keffs))
pprint(list(keffs.available_values('keff_estimator')))
4
['KSTEP', 'KCOLL', 'KTRACK', 'MACRO KCOLL']
Dans ce cas il y a un autre estimateur en plus : 'MACRO_KCOLL'. À noter également la présence du nombre de batches discarded puisqu’il est calculé par Tripoli-4.
Exemples de comparaison de
Différents tests sont disponibles dans valjean. Par exemple :
TestEqualqui vérifie que les datasets sont égaux (ce test est plutôt prévu pour des valeurs entières comme les nombres de batches)TestApproxEqualqui vérifie que les datasets sont approximativement égaux (pertinent pour lesfloatpour lesquels on n’a pas d’erreur associée, les corrélations de par exemple)TestStudentdans le cas où l’on veut prendre en compte les erreurs sur les valeurs
Pour tous ces tests il faut définir une référence, qui sera le premier dataset donné au test.
L’exemple ci-dessous présente la comparaison des obtenus grâce à la modélisation simplifiée utilisée ci-dessus à celle du modèle en couches décrit dans heu-met-fast-001-shell_model.
On utilisera les “génériques” en comparant tous les estimateurs un à un.
[11]:
sb = t4b.filter_by(response_function='KEFFS')
print('estimators values:', list(sb.available_values('keff_estimator')))
estimators values: ['KSTEP', 'KCOLL', 'KTRACK', 'KSTEP-KCOLL', 'KSTEP-KTRACK', 'KCOLL-KTRACK', 'full combination']
Tous les sont récupérés et stockés dans une liste. L’estimateur sera utilisé comme 'name' pour chaque Dataset.
[12]:
dsets = []
for keff in sb.content:
dsets.append(keff['results']['keff'])
dsets[-1].name=keff['keff_estimator']
# print(dsets)
Pour rendre le résultat plus lisible un seul Dataset va être construit, contenant tous les pour une modélisation donnée. Les bins correspondent alors aux noms des estimateurs, actuellement stockés dans la variable 'name' des Dataset.
[13]:
from collections import OrderedDict
import numpy as np
from valjean.eponine.dataset import Dataset
[14]:
dset_simple = Dataset(value=np.array([k.value for k in dsets]),
error=np.array([k.error for k in dsets]),
bins=OrderedDict([('estimator', np.array([k.name for k in dsets]))]),
name='Simple model', what='keff')
[15]:
print(dset_simple)
shape: (7,), dim: 1, type: <class 'numpy.ndarray'>, bins: ["estimator: ['KSTEP' 'KCOLL' 'KTRACK' 'KSTEP-KCOLL' 'KSTEP-KTRACK' 'KCOLL-KTRACK' 'full combination']"], name: Simple model, what: keff
Un Dataset similaire est construit pour la modélisation en couche.
[16]:
t4p_shell = Parser('heu-met-fast-001-shell_model.res')
t4b_shell = t4p_shell.parse_from_index().to_browser()
INFO parse: Parsing heu-met-fast-001-shell_model.res
INFO parse: Successful scan in 0.036796 s
INFO parse: Successful parsing in 0.026962 s
[17]:
sb_shell = t4b_shell.filter_by(response_function='KEFFS')
ldsets_shell = []
for keff in sb_shell.content:
ldsets_shell.append(keff['results']['keff'])
ldsets_shell[-1].name=keff['keff_estimator']
[18]:
dset_shell = Dataset(value=np.array([k.value for k in ldsets_shell]),
error=np.array([k.error for k in ldsets_shell]),
bins=OrderedDict([('estimator', np.array([k.name for k in ldsets_shell]))]),
name='Shell model', what='keff')
On importe les tests et la possibilité d’en faire des représentations
[19]:
from valjean.gavroche.stat_tests.student import TestStudent
from valjean.javert.representation import FullRepresenter
from valjean.javert.rst import RstFormatter
from valjean.javert.mpl import MplPlot
from valjean.javert.verbosity import Verbosity
frepr = FullRepresenter()
rstformat = RstFormatter()
La comparaison sera faite grâce à un TestStudent pour prendre en compte les erreurs statistiques de Tripoli-4.
[20]:
tstud_res = TestStudent(dset_simple, dset_shell, name='TestStudent',
description='Test le TestStudent sur les keff').evaluate()
print(bool(tstud_res))
True
[21]:
stud_temp = frepr(tstud_res, verbosity=Verbosity.FULL_DETAILS) # il s'agit d'une liste de templates
stud_rst = rstformat.template(stud_temp[1])
print(stud_rst)
.. role:: hl
.. table::
:widths: auto
================ =============== =============== ============== ============== =========== ========
estimator v(Simple model) σ(Simple model) v(Shell model) σ(Shell model) t Student?
================ =============== =============== ============== ============== =========== ========
KSTEP 0.997857 0.000859893 0.996782 0.000882087 0.872579 True
KCOLL 0.996761 0.000680173 0.996412 0.000701962 0.357056 True
KTRACK 0.99686 0.000611041 0.99573 0.00061235 1.30649 True
KSTEP-KCOLL 0.99676 0.000680173 0.99641 0.00070196 0.357363 True
KSTEP-KTRACK 0.996962 0.000607047 0.995797 0.000610815 1.35352 True
KCOLL-KTRACK 0.996834 0.000600633 0.99586 0.00060659 1.14052 True
full combination 0.996834 0.000600633 0.99586 0.000606584 1.14053 True
================ =============== =============== ============== ============== =========== ========
[22]:
mpl = MplPlot(stud_temp[0]).draw()
